Understanding cloaking in SEO starts with one core rule: the indexed meaning of a page should match what a human user actually gets. Once a server begins showing one version of the content to bots and another version to people, it crosses from technical optimization into deceptive delivery.
Updated for April 2026, this guide reflects the current Google spam policy on cloaking and how it now applies to AI crawlers and answer-engine retrieval as well as classic search bots.
That distinction matters more now because JavaScript-heavy websites often struggle to expose complete HTML to crawlers on the first response. Teams sometimes react by building user-agent routing or proxy behavior that looks like a rendering fix but drifts into semantic mismatch. The safe path is not to hide different content behind bot detection. The safe path is to preserve semantic parity while changing only the delivery format. That is why this topic sits close to JavaScript SEO, prerendering, and crawl budget optimization for JavaScript sites, not just to spam policy discussions.

This article explains what cloaking is, how it works technically, why search engines penalize it, how dynamic rendering differs from deception, and how prerendering infrastructure can solve machine-readability problems without violating search guidelines.
What Is Cloaking in SEO?
Cloaking in SEO is the practice of serving materially different content to search engine crawlers than to human visitors. The difference is not just presentation or transport format. The difference is the actual informational payload, intent, or outcome of the page.
A cloaked route often behaves like this:
- the crawler receives a highly optimized HTML document full of target keywords
- the human visitor receives a different page, offer, redirect, or experience
- the indexed promise of the page no longer matches the real destination
Why cloaking is a trust violation, not a technical preference
That is why cloaking is treated as a quality and trust violation. Search engines are trying to index what users will actually see. If the bot is shown one thing and the user gets another, the search engine can no longer trust the route as a valid result, which is the practical reasoning behind Google's dynamic rendering documentation treating equivalence rather than identical bytes as the compliance bar. In practice, teams usually uncover these issues during a technical SEO audit when bot-facing HTML is compared against the live rendered route.
How Does SEO Cloaking Work Technically?
Most cloaking setups rely on conditional routing at the server, proxy, or middleware layer. The system inspects the incoming request and decides which response to send based on signals associated with bots or humans. If you want the compliant operational version of this same routing layer, the companion article on bot detection and offloading bot visits shows how teams can separate verified crawlers from suspicious automation without changing page intent.
Common detection inputs include:
User-Agentstrings such asGooglebotorBingbot, validated against Google's verifying Googlebot guide- crawler IP ranges or reverse DNS validation
- header patterns
- geography or network source
- execution context differences between bots and browsers
The problem is not the presence of request inspection by itself. Many systems inspect traffic for caching, security, or rendering purposes. The problem begins when that inspection is used to change the page's semantic meaning.
How cloaking systems use bot detection to swap content
For example, a cloaking system may:
- send a keyword-rich HTML article to crawlers
- send a different commercial landing page to users
- redirect users to a separate destination after the bot has indexed the original URL
- hide monetized or restricted content from crawler review
At that point, the route is no longer an optimization tactic. It is deceptive delivery.
Why Do Search Engines Penalize Cloaking?
Search engines penalize cloaking because it breaks the basic contract between indexed content and user experience. The ranking system is supposed to help users discover pages that fulfill the promise made in search results. Cloaking severs that relationship.
From an algorithmic perspective, cloaking creates several risks:
- users click expecting one thing and land on another
- quality systems lose trust in the page representation
- spam, redirects, and affiliate abuse become harder to detect
- the search result no longer reflects the real destination
How search engines detect cloaked routes
Modern detection systems compare what the declared crawler receives against what other fetching environments receive. That can include headless rendering, alternate IP ranges, or manual review. When the content delta is too large, the route can be demoted or the domain can receive a manual action.
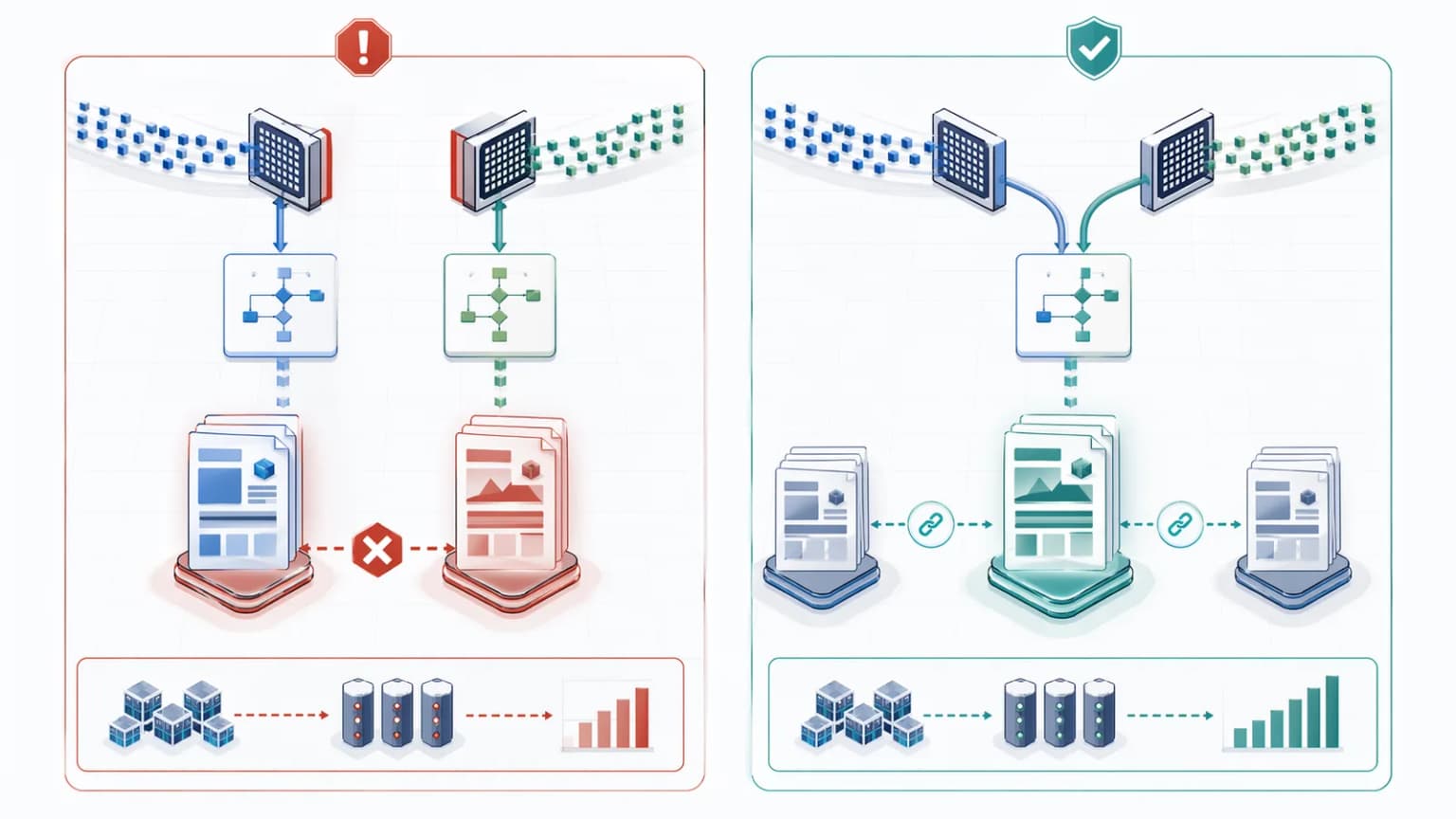
Cloaking vs Dynamic Rendering: What Is the Real Difference?
The real difference is semantic parity.
Dynamic rendering or prerendering is compliant when the bot receives the same meaning, facts, entities, and page intent that a human receives. The machine-facing version may be serialized HTML while the human version is an interactive JavaScript application, but both versions still describe the same page.
| Delivery model | Human receives | Bot receives | Semantic parity | Compliance |
|---|---|---|---|---|
| Malicious cloaking | Different commercial or unrelated page | Optimized keyword page | No | Unsafe |
| Client-side rendering only | JavaScript app | Thin or incomplete HTML shell | Partial or unstable | Risky for visibility |
| Compliant prerendering | Interactive app | Serialized HTML snapshot of the same page | Yes | Safe |
The distinction is simple but strict:
- cloaking changes the meaning of the page
- prerendering changes the delivery format of the same page
That is why prerendering can be a legitimate rendering strategy while cloaking remains a violation. If you want the positive version of this architecture, the guide on what websites benefit from a prerendering service covers when machine-facing rendering is actually justified.
Why JavaScript Sites Sometimes Drift Toward Risky Delivery Logic
Single-page applications and hybrid frontends often expose a weak first response. Instead of useful HTML, the route may return a shell that requires hydration, API calls, and client-side execution before any meaningful content appears.
That creates pressure on technical teams because bots and AI retrieval systems do not always wait for the page to stabilize. When visibility suffers, teams start looking for workarounds. If those workarounds are poorly designed, they can drift toward cloaking behavior even when the original intent was only to improve crawlability.
Common ways teams accidentally drift into cloaking
This happens when teams:
- build bot-only fallback pages with different copy
- inject crawler-facing text that users never see
- forget to keep prerendered snapshots in sync with live content
- cache machine-facing content separately from human-facing updates
- let metadata or schema diverge between responses
The lesson is not to avoid machine-aware delivery altogether. The lesson is to validate parity carefully. This is also where a view as bot vs prerender tool becomes practical rather than theoretical.
What Makes Prerendering Compliant?
Prerendering is compliant when it helps crawlers read the same page more reliably instead of showing them a different page.
In a compliant setup:
- the prerendered HTML reflects the final rendered state of the route
- the headings, body copy, links, and entities stay consistent
- metadata and canonical signals match the live page intent
- the rendered snapshot is refreshed when source content changes
- personalized or authenticated content is excluded from crawler-facing snapshots
The safest mental model is this: prerendering should make the page easier to fetch and parse, not easier to manipulate. The wider implementation tradeoffs are covered in the external breakdown of prerendering middleware.
Implementing Safe Prerendering with Semantic Parity
For JavaScript-heavy sites, prerendering middleware can solve machine-readability problems without changing the meaning of the route. The proxy detects bot-like traffic, renders the page in a controlled environment, and returns deterministic HTML that reflects the real page state.
At a high level, the compliant path looks like this:
- A bot requests a route.
- Proxy logic routes the request to a prerendering layer.
- The application renders fully in a headless browser.
- The resulting HTML snapshot is returned to the bot.
- Human users still receive the normal interactive app.
This remains safe only if the content stays aligned across both paths.
What technical teams should validate during rollout

Technical teams should validate:
- raw HTML before hydration
- schema presence in the first response
- canonical consistency
- cache freshness after content updates
- route behavior under bot-like fetch conditions
- exclusions for authenticated and personalized pages
Common Failure Modes That Mimic Cloaking
Not every mismatch is malicious. Some sites accidentally create cloaking-like conditions through weak rendering operations or stale delivery layers.
The most common accidental failure modes are:
- stale prerendered snapshots after a CMS update
- bot-facing metadata that differs from the human route
- geo-routing or cookie-based logic that changes page meaning
- incomplete rendering where sections fail to load in the prerendered output
- caching rules that serve the wrong variant to crawlers
These issues may not be intentional, but they still create trust problems. If the machine sees a materially different document than the user, the route becomes harder to evaluate and easier to distrust.
How to Audit a Route for Cloaking Risk
If a team is unsure whether its rendering setup is compliant, the fastest path is to compare the machine-facing output with the human-facing result after the page fully stabilizes.
What a strong cloaking-risk audit checks
A strong audit checks:
- HTML returned to the crawler
- visual and semantic parity after hydration
- internal links and canonical behavior
- structured data consistency
- redirects triggered by user state, geography, or scripts
- cache invalidation after content changes
The goal is not perfect byte-for-byte equality. The goal is parity of meaning, structure, and destination. Teams often verify the structured-data side of that parity with a JSON-LD validator before rollout.

Conclusion
Cloaking in SEO is not just about detecting bots. It is about using bot detection to change what the page fundamentally is. That is why search engines treat it as a serious trust violation.
Compliant prerendering solves a different problem. It helps crawlers and AI systems read JavaScript-heavy pages by changing the delivery format, not the page meaning. When semantic parity is preserved, prerendering becomes a legitimate technical SEO pattern rather than a deceptive one.
For engineering teams, the practical rule is straightforward: if a machine-facing route exists, it should be easier to parse, not different in intent. The closer the prerendered snapshot is to the fully rendered human experience, the safer the architecture becomes.
Content Cocoon
SEO Cloaking Editorial Cluster
This article should connect cloaking-related technical risk back to compliant rendering systems, audit work, and the implementation paths that preserve semantic parity for crawlers.
Internal Pathways
Technical SEO Audit
The parent service for teams that need rendering, crawlability, and compliance issues audited together.
Prerendering
A related service when teams need machine-readable HTML without changing the underlying content intent.
JavaScript SEO
Relevant when thin initial HTML or unstable rendering is pushing teams toward risky delivery workarounds.
SEO for ChatGPT
A companion article showing how compliant machine-facing delivery supports AI retrieval without cloaking.
External Technical References
Prerendering Middleware Explained
Useful for understanding why prerendering changes delivery format without changing semantic intent.
HTTP Status Codes for Bots
Helpful when validating whether bots receive stable, compliant responses.
Prerender Checker
A practical tool for comparing machine-facing HTML against the intended rendered output.
Frequently Asked Questions
What is cloaking in SEO?+
Cloaking in SEO is serving materially different content to search engine crawlers than to human users, causing the indexed meaning of the page to diverge from the real destination.
Is dynamic rendering the same as cloaking?+
No. Dynamic rendering is compliant when it preserves semantic parity and changes only the delivery format, such as returning serialized HTML for bots while humans get the interactive version of the same page.
Why can prerendering still become risky?+
Prerendering becomes risky when snapshots go stale, metadata diverges, or the machine-facing version stops matching what users actually receive after the page fully renders.
How can teams validate that prerendering is compliant?+
They should compare bot-facing HTML against the fully rendered human route, check metadata and schema consistency, validate cache freshness, and exclude personalized or authenticated pages from crawler-facing delivery.