Bot detection becomes strategically important when automated traffic starts consuming expensive rendering resources or distorting crawler-facing delivery paths. On modern JavaScript-heavy websites, not every automated request should be treated the same way. Some bots are legitimate search and AI retrieval systems that need machine-readable HTML. Others are abusive scrapers or synthetic traffic sources that create load without business value.
Updated for April 2026, this guide reflects the current Google guidance on verifying Googlebot along with the published bot directories from major AI vendors.
That is why bot detection is not only a security concern. It is also a rendering and infrastructure concern. Once the edge layer can distinguish beneficial crawler traffic from untrusted automation, the site can route those visits more intelligently. Verified bots can be offloaded into a prerendering path, while the origin stays focused on human traffic and core application workloads. This sits directly between prerendering, JavaScript SEO, route-level AI search visibility, and the broader prerendering vs SSR vs SSG decision guide.

This article explains how bot detection works, what a positive bot classification should mean operationally, how prerendering helps offload legitimate crawler visits, and what technical teams should validate when routing automated traffic away from the origin.
What Is Bot Detection and How Does It Work?
Bot detection is the process of classifying incoming traffic as automated or human based on request-level, network-level, and behavioral signals. The goal is not simply to block automation. The goal is to decide how different classes of traffic should be handled.
At the infrastructure level, detection usually relies on:
- declared
User-Agentstrings, cross-checked against the Googlebot user-agent reference - IP ranges and reverse DNS verification
- TLS or request fingerprinting
- request velocity and access patterns
- header consistency and session behavior
Why detection is about routing, not blocking
This matters because not all automated traffic is malicious. Search engines, answer engines, social preview bots, uptime tools, and internal QA systems may all need access. The real problem is routing the wrong traffic into the wrong delivery path. That distinction becomes especially important once teams start optimizing for answer engines such as ChatGPT, Perplexity AI, or Microsoft Copilot.
Why Bot Detection Matters for Server Architecture
On JavaScript-heavy websites, automated traffic can become expensive because every request may trigger rendering logic, API calls, cache lookups, and downstream application work. If the site treats every machine request like a normal user session, the origin can absorb crawler load that should have been diverted elsewhere.
That is where bot detection becomes operationally useful. A positive bot classification can trigger a routing decision instead of a generic allow-or-block decision. For example:
- verified search bots can receive prerendered HTML
- social crawlers can receive metadata-friendly output
- abusive scrapers can be blocked or rate-limited
- internal testing bots can bypass specific controls safely
Why detection belongs in a technical SEO audit
This is one reason bot detection often belongs inside a broader technical SEO audit rather than only inside an application firewall review.
How to Detect Bots at the Network Edge
Reliable bot detection usually starts at the reverse proxy or edge gateway, before the request reaches the core application. The earlier the system can classify the traffic, the easier it becomes to protect the origin from unnecessary work.
The strongest edge-level signals usually include:
- reverse DNS checks for known crawler infrastructure
- IP reputation for data-center and scraping traffic
- TLS handshake and request fingerprint anomalies
- unrealistic navigation and request timing patterns
- mismatch between declared client identity and network origin
Why a single signal is never enough
The key is not overfitting to one signal. User-Agent matching alone is too weak because it is easy to spoof. Teams usually need a layered model that combines identity verification with request behavior and routing context. If the team needs a broader implementation baseline, the guide on what websites benefit from a prerendering service is a useful companion.
The taxonomy below summarizes how the major bot classes seen in production logs are typically identified and handled. The User-Agent and IP verification methods come from each vendor's own documentation, including Google's common crawlers reference, Bing's published crawler list, and Perplexity's bot guide:
| Bot class | User-Agent pattern | IP verification method | Recommended action |
|---|---|---|---|
| Search engines | Googlebot, bingbot, DuckDuckBot | Reverse DNS plus forward DNS to vendor zone | Route to prerender, full crawl access |
| AI crawlers | GPTBot, ClaudeBot, PerplexityBot | Vendor-published IP CIDR allowlist | Route to prerender, respect robots.txt directives |
| Social previews | facebookexternalhit, Twitterbot, LinkedInBot | Known datacenter ranges, UA pattern | Serve metadata-rich snapshot, no full prerender needed |
| Scrapers | Spoofed UA, headless browser fingerprints | Reverse DNS fails, residential proxy heuristics | Rate-limit or block at edge |
| Monitoring tools | UptimeRobot, Pingdom, internal QA UA | Static IP allowlist | Bypass detection, return live origin |
What Does "Bot Detected" Actually Mean?
In a healthy architecture, "bot detected" should not mean the same thing for every class of automated traffic. It should mean that the request has entered a conditional decision tree.
That tree may lead to:
- a prerendering path for verified crawler traffic, including OpenAI's documented bots and PerplexityBot
- a lightweight static response for preview bots
- a challenge or deny rule for suspicious automation
- a whitelisted bypass for QA or monitoring systems
From reporting feature to infrastructure control
This is where detection stops being a reporting feature and becomes an infrastructure control. Once classification is tied to routing, the system can reduce waste, preserve origin capacity, and improve crawler-facing reliability at the same time. In practice, that usually becomes part of the same implementation discussion as prerendering for technical SEO.
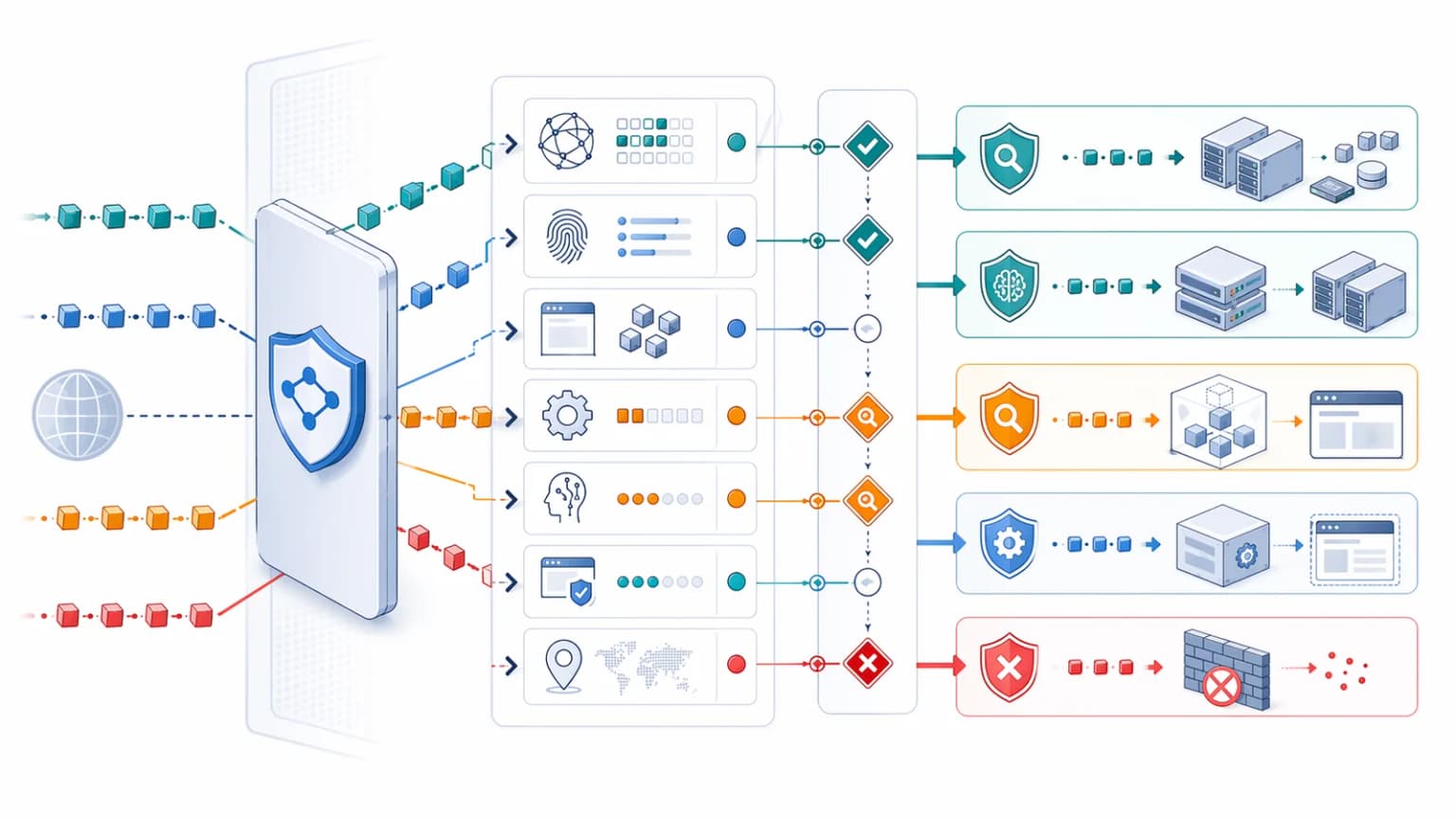
Why Offload Verified Bot Visits to Prerendering?
For legitimate crawlers, the best outcome is often not to serve the raw JavaScript application directly from the origin. It is to return a deterministic HTML snapshot that already contains the important content, metadata, and structure.
That is why teams offload verified bot visits to a prerendering layer. Instead of forcing every search or AI bot to execute the frontend stack deeply, the reverse proxy can route that traffic into a controlled rendering environment and return machine-readable HTML immediately.
At a high level, the flow looks like this:
- A machine request reaches the edge.
- Bot detection classifies the request.
- Verified crawler traffic is routed to prerendering.
- The route is rendered into stable HTML.
- The bot receives the snapshot while the origin is insulated from the heavy rendering workload.
This is especially useful when the website already suffers from JavaScript SEO issues or hydration-heavy routes.
Bot Detection vs Cloaking: Where Teams Get Nervous
Bot-aware delivery can look risky if teams are not careful, because changing the response path for bots raises an obvious compliance question. The safe distinction is the same one that matters across all prerendering work: semantic parity.
If verified bots receive the same page meaning in a different delivery format, the pattern can stay compliant. If bots receive a different destination, different claims, or a different content intent, the architecture drifts into cloaking territory. That is why teams implementing bot routing should also understand what cloaking is in SEO.
The semantic parity rule in practice
The practical rule is simple:
- change the rendering path, not the meaning of the page
- validate the crawler-facing snapshot against the final rendered route
- keep metadata, canonicals, and schema aligned
That is also why bot-aware routing has to be validated against the compliance rules covered in what is cloaking in SEO, not treated as a purely defensive network pattern.
How Prerendering Middleware Fits Into Bot Routing
Prerendering middleware sits between the proxy decision and the final machine-facing response. Once the edge has enough confidence that the request belongs to a verified crawler, the middleware can generate the deterministic HTML that search and AI systems need.
This reduces origin pressure because:
- rendering work happens outside the primary user-serving path
- repetitive machine requests no longer hammer the application directly
- bots receive a stable response faster
- the site can separate human performance from crawler delivery concerns
For teams that need a broader decision framework, the guide on what websites benefit from a prerendering service is a useful companion.
Risks and Limitations of Bot Detection Systems
Aggressive bot detection can easily create false positives if the system blocks or misroutes traffic that is actually useful. This is why classification rules must be operationally conservative and well-monitored.
The most common risks include:
- blocking legitimate crawlers after IP changes
- sending expensive prerendering capacity to spoofed traffic
- breaking payment, CMS, or webhook integrations
- caching the wrong machine-facing variant
- denying internal QA environments unintentionally
Treat false positives as infrastructure incidents
These are infrastructure problems, not only security problems. Teams need clear allowlists, audit logs, and validation steps so routing decisions can be inspected after deployment. That operational view overlaps strongly with the article on AI visibility tooling, where delivery diagnostics matter as much as reporting.
How to Validate Bot Detection and Offload Logic
Once bot routing is live, teams should validate both the classification quality and the resulting output. It is not enough to confirm that the bot was detected. The machine-facing response also has to be correct.
A strong validation process checks:
- whether verified bots were routed to the expected path
- whether prerendered HTML is complete and current
- whether metadata and schema remained intact
- whether origin load drops during crawler traffic spikes
- whether suspicious automation was denied without harming beneficial bots
Tools for inspecting bot-facing output
Teams usually compare outputs with a view as bot vs prerender tool and use a prerender checker for route-level QA.
For ad-hoc verification of a single Googlebot IP address, the official two-step reverse DNS check can be run from any shell. The first command resolves the IP back to a hostname; the second command resolves that hostname forward and should return the original IP:
# Step 1: reverse DNS lookup for the visiting IP
host 66.249.66.1
# expected: 1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
# Step 2: forward DNS lookup on the returned hostname
host crawl-66-249-66-1.googlebot.com
# expected: crawl-66-249-66-1.googlebot.com has address 66.249.66.1
If both lookups match and the hostname ends in googlebot.com or google.com, the request is a verified Googlebot. Any mismatch means the User-Agent is spoofed and the traffic should not be routed to the prerender path.

Comparing Traffic Handling Strategies
Different teams solve bot traffic in different ways, but the architectural tradeoffs are usually clear:
| Strategy | Crawler output quality | Origin compute load | Operational control |
|---|---|---|---|
| Serve all bots from origin | Inconsistent on JS-heavy sites | High | Low |
| Block aggressively | Poor for legitimate bots | Low | Medium |
| Static allowlist only | Better, but fragile | Medium | Medium |
| Detect, classify, and offload verified bots | High | Low to moderate | High |
For many JavaScript-heavy teams, the last model is the strongest because it supports both technical SEO and infrastructure resilience at the same time. Teams still comparing rendering strategies should also review the broader SSR vs prerendering framing before rollout.
Conclusion
Bot detection is most valuable when it supports better routing decisions, not just stricter blocking. On modern websites, that usually means separating verified crawler traffic from suspicious automation and sending useful bots into a prerendering path that protects the origin and improves machine-readable delivery.
The winning pattern is not simply "detect bots." It is "detect, classify, and route correctly." When semantic parity is preserved and machine-facing HTML stays stable, bot detection becomes part of a healthier technical SEO and rendering architecture rather than a separate defensive layer.

Content Cocoon
Bot Detection Editorial Cluster
This article should connect bot-detection and routing topics back to prerendering, JavaScript SEO, and technical audit work, while clarifying the operational distinction between legitimate crawler handling and malicious bot mitigation.
Internal Pathways
Prerendering
The core service page for teams that need deterministic machine-facing HTML for verified crawler traffic.
JavaScript SEO
Relevant when bot offloading exists because JavaScript-heavy routes are too expensive or unreliable for crawler-facing delivery.
Technical SEO Audit
Useful when routing, rendering, bot handling, and indexation quality need to be audited together.
What Is Cloaking in SEO?
A companion article for teams that need to keep bot routing compliant and semantically aligned.
External Technical References
Prerendering Middleware Explained
Useful for understanding how reverse-proxy routing and prerendering clusters work together.
Prerender Checker
Helpful for validating the machine-facing HTML returned after bot routing decisions.
View as Bot vs Prerender
A practical tool for comparing crawler-facing output against the intended prerendered response.
Frequently Asked Questions
What is bot detection in website infrastructure?+
Bot detection is the classification of incoming traffic as automated or human using signals such as headers, IP reputation, reverse DNS, request fingerprints, and behavioral patterns.
Why offload verified bot visits to prerendering?+
Because legitimate crawlers often need machine-readable HTML, while prerendering lets the site serve that output without forcing the origin to absorb heavy rendering work for every automated request.
Is bot-aware routing the same as cloaking?+
No. It becomes risky only when the routing changes the meaning or destination of the page. Safe bot-aware delivery changes the rendering path while preserving semantic parity.
How should teams validate bot routing after launch?+
They should confirm classification quality, inspect prerendered output, compare bot-facing HTML with the final rendered route, and verify that origin load improves without harming beneficial crawlers.